- Project page here
- Paper on arXiv
- Code available here
- Dataset on Hugging Face
Ask your AI assistant a question that should be trivial — “What was the gift I bought for my mom during our Japan trip last year — is it still under warranty?” — and watch it fail. Not because the model is small, not because the context window is short, but because no current system knows how to organise a person’s life into something it can reason over. ATM-Bench (According To Me) is the first benchmark that measures this failure honestly: it is built from four years of my own multimodal personal data — photos, videos, emails, receipts — and contains 1,069 human-annotated question–answer pairs with grounded evidence. Every question is the kind of thing you would actually ask a personal assistant. Every answer requires resolving personalised references, fusing cross-modal evidence, and choosing between conflicting documents. The headline finding, on the live leaderboard, is a ~50-point gap between the Oracle ceiling (GPT-5.5 at 71.49% on the Hard split) and the best end-to-end system (Codex + GPT-5.5 at 48.10%, at $39.74/run), and that gap is the whole paper.
ATM-Bench demo — exploring four years of personal data as a test suite
Why current memory systems fail
We evaluated four families of systems against ATM-Bench on the live leaderboard. Specialised memory architectures (A-Mem, HippoRAG2, mem0, MemoryOS, MemPalace, ScrapMem, SimpleMem) sit in a 3–14% band on the Hard split — sophisticated retrieval, knowledge graphs and structured storage all underperform by a wide margin because none of them were built for lived multimodal data. RAG pipelines (HippoRAG2, ATM-RAG) sit in the same band. General-purpose coding agents with full file-system access — Codex, Claude Code, Pi, OpenCode, OpenClaw — climb to 30–48% only by brute-force exploring the data. Oracle runs with the gold evidence pre-injected reach ~72%. The pattern is the same on the full set: a 30+ point gap between every system and the Oracle ceiling, and a 15+ point gap between Oracle and “perfect,” which says the problem is not model scale and not retrieval alone.
The failures cluster around three challenges that prior benchmarks never isolate:
1. Personalised reference resolution. When the user says “the moments where Grace was being sneaky”, the system has to resolve Grace (friend, family, pet?), track her across years of photos and videos, and interpret a subjective descriptor. Off-the-shelf RAG has no schema for this.
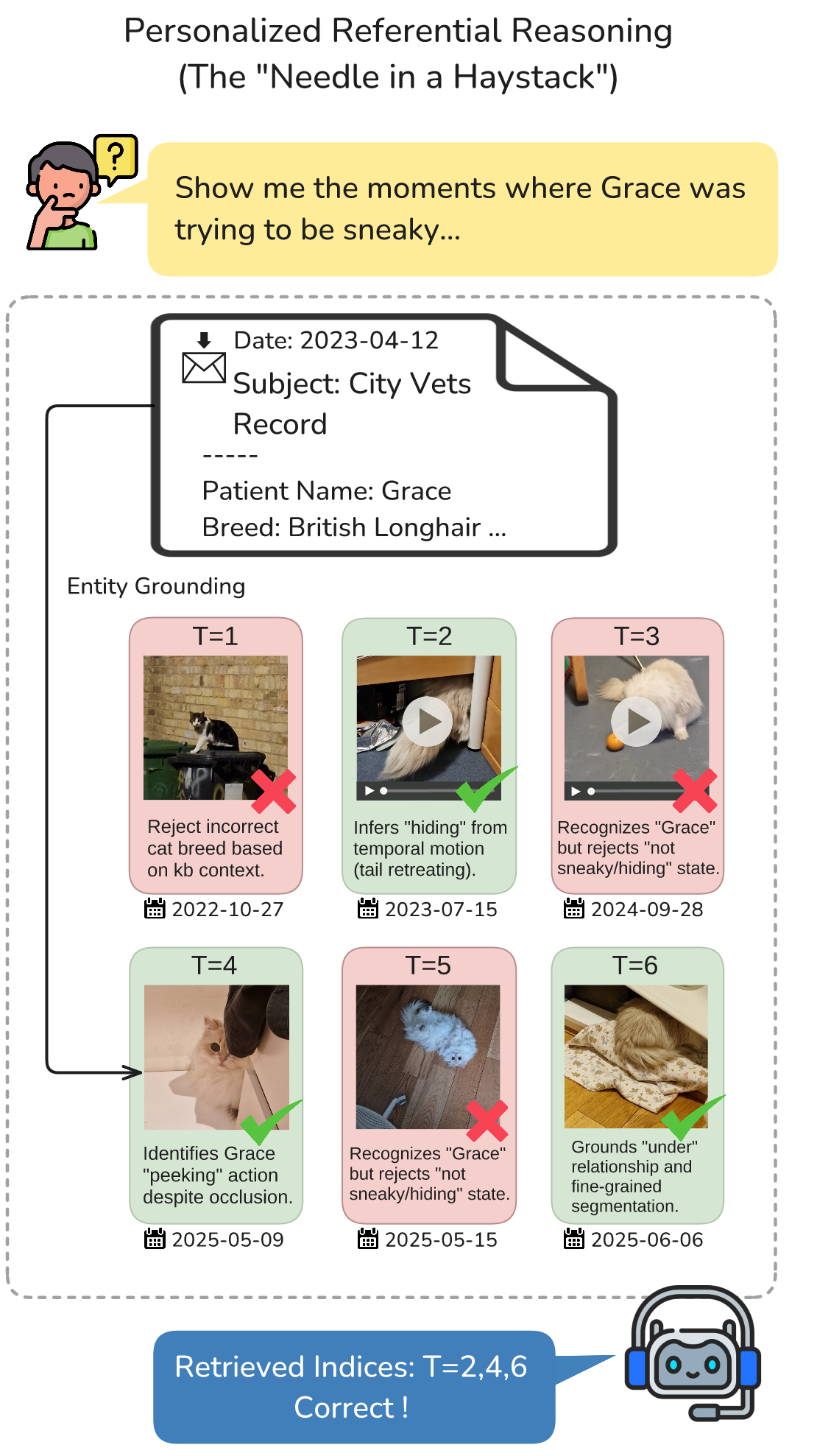
2. Conflict resolution. A hotel stay in Portugal has a booking confirmation, a final invoice, and a credit-card receipt — and they disagree. The right answer is whichever one is most recent and authoritative; the easy answer is whichever one retrieval surfaces first. GPT-5 often grabs the outdated booking email.

3. Cross-modal association. The restaurant name “Fancett” only appears in the email confirmation — the photos from that dinner have no GPS tags. Answering requires locating the email, extracting a time window, retrieving photos from that window, and visually identifying the food.

All three challenges are absent from existing memory benchmarks (LoCoMo, MSC, LongMemEval), which are built from synthetic or dialogue-only data. ATM-Bench is the first to make them the test.
Method
ATM-Bench is built from one person’s data, but its design and scoring are general.
Data construction. Four years of the author’s personal archive — phone photos and videos, booking emails, university correspondence, receipts — were ingested and time-aligned. 1,069 question–answer pairs were written, verified, and grounded to a specific set of evidence items. Each item carries (a) the question, (b) one or more gold evidence references, and (c) a human-verified answer.
Splits. The benchmark ships three views:
- ATM-Bench (full): the 1,069 pairs in their natural distribution. Designed to surface the easy recall wins that a tuned memory system can capture.
- ATM-Bench-Hard: the subset where the question requires multi-hop reasoning, conflict resolution, or cross-modal association. This is the split the leaderboard headline reads.
- ATM-Bench-Hard-NIAH-100: the long-context stress test where gold evidence is buried among 100 distractors. Designed to expose the “million-token context, 11% accuracy” failure mode (see below).
Metrics. Two reported numbers: QuestionScore (QS) — exact-match / model-judged correctness of the final answer — and Recall@10 — whether the system’s top-10 retrieved items contain all gold evidence (a clean retrieval diagnostic, reported only for systems with a retrievable index).
The Schema-Guided Memory (SGM) baseline. SGM is the architecture ATM-Bench argues for. Each memory item is represented as a structured record with explicit fields — time, location, entities, tags, modality, source — rather than as free-form descriptive text. Retrieval becomes a structured query (filter by time/location, then match entities/tags) rather than a semantic lookup against a description blob. The intuition: structured fields are the only way to make “dinner in Sligo on January 30th” tractable to a retriever without re-parsing natural language on every query.
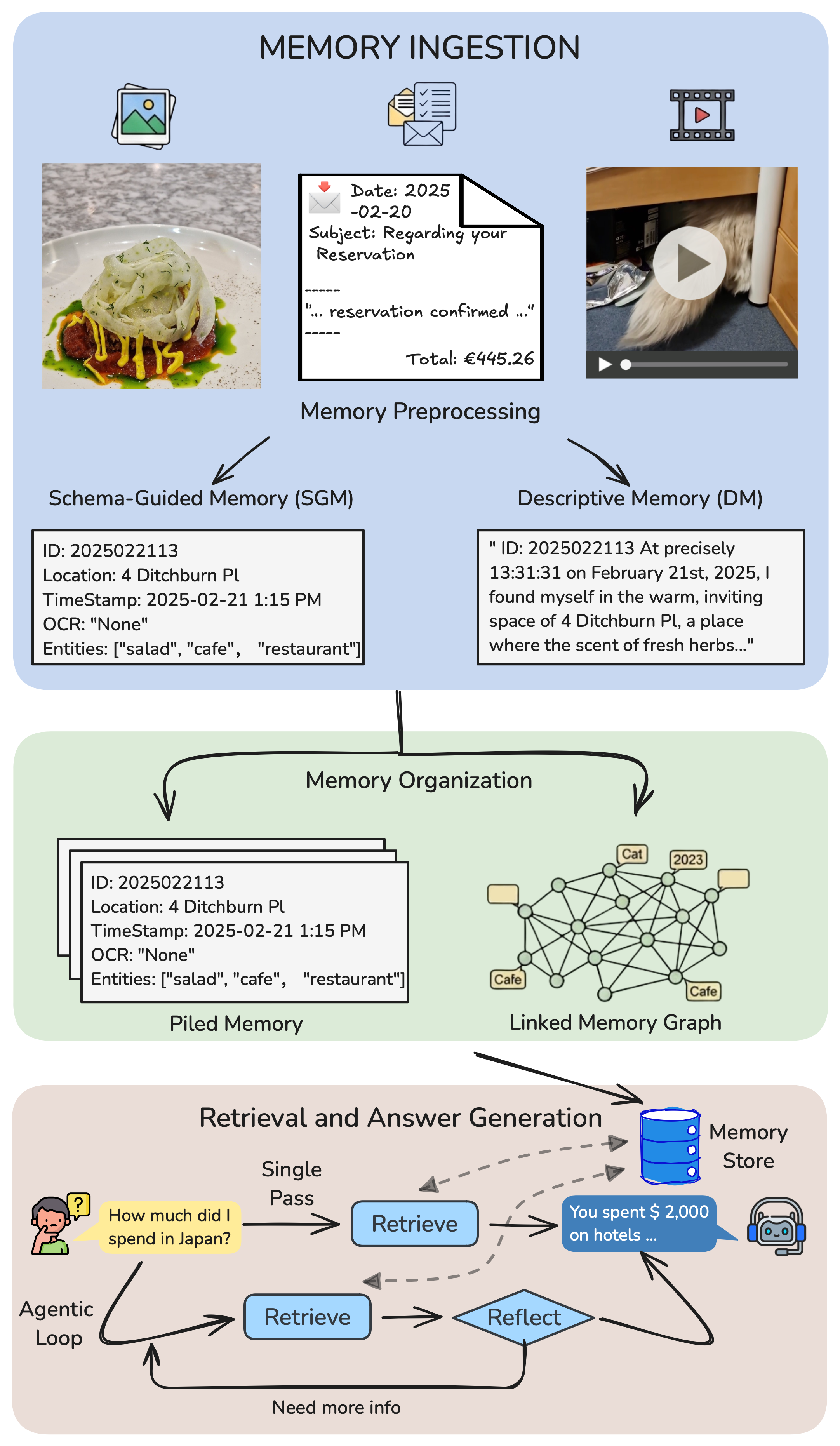
SGM is not a winning system — it tops out under 30% on Hard — but it consistently beats the Descriptive Memory baseline by 5–10 QS points across every system we tested. That gap is the architectural signal ATM-Bench is designed to expose: explicit structure beats implicit understanding, even when both are retrieval-augmented.
Experiments
All numbers below are pulled from the live leaderboard. We report results across the four system families and the NIAH stress test, with Schema-Guided Memory (SGM) as the harness scaffold for every agent run unless noted otherwise.
Specialised memory & RAG systems on ATM-Bench-Hard.
| Class | System | QS | Recall@10 |
|---|---|---|---|
| Memory | MemoryOS | 13.70% | 32.7% |
| Memory | A-Mem | 9.90% | 31.7% |
| Memory | MemPalace | 9.70% | 28.3% |
| Memory | Mem0 | 9.20% | 23.7% |
| Memory | SimpleMem | 3.20% | 7.0% |
| RAG | ATM-RAG (ours) | 13.80% | 30.4% |
| RAG | HippoRAG2 | 9.40% | 31.9% |
Every system sits in a 3–14% band. Sophisticated retrieval, knowledge graphs, and structured storage all underperform by a wide margin because none of them were built for lived multimodal data.
General-purpose agents on ATM-Bench-Hard.
| Harness | Model | QS | Tokens / run | Cost / run |
|---|---|---|---|---|
| Codex | GPT-5.5 (xhigh) | 48.10% | 22.89M | $39.74 |
| Claude Code | Claude Opus 4.7 (max) | 46.60% | 6.93M | $9.58 |
| Pi | MiniMax M3 | 43.23% | 15.60M | $3.39 |
| Codex | GPT-5.5 (medium) | 41.40% | 16.14M | $27.17 |
| Claude Code | Claude Opus 4.8 | 41.60% | 4.42M | $7.49 |
| Codex | GPT-5.2 | 39.70% | 15.46M | — |
| Claude Code | Claude Opus 4.7 (xhigh) | 39.50% | 5.03M | $7.70 |
| Pi | GLM-5.1 | 38.80% | 8.17M | $4.33 |
| Pi | Qwen3.6-27B | 38.53% | 7.15M | $2.45 |
| Pi | Kimi K2.5 | 37.80% | 9.92M | $2.67 |
| Pi | MiMo V2.5 | 36.10% | 18.23M | $2.06 |
| Claude Code | Claude Opus 4.6 | 33.80% | 4.93M | $8.01 |
| Pi | MiMo V2.5 Pro | 31.95% | 14.57M | $4.98 |
| OpenCode | Kimi K2.5 | 30.30% | 8.46M | $1.81 |
| Codex | GPT-5.4 | 29.60% | 14.29M | $9.33 |
| OpenCode | MiniMax M2.7 | 27.80% | 13.48M | $1.36 |
| OpenCode | GLM-5 | 27.00% | 16.89M | $14.92 |
| OpenClaw | Kimi K2.5 | 25.40% | 9.63M | $2.37 |
| OpenCode | Qwen3.5-397B-A17B | 24.50% | 12.06M | $4.93 |
| OpenCode | MiniMax M2.5 | 22.90% | 14.5M | $4.43 |
Agents beat memory systems by being able to explore: they grep, list, open, and re-read. The new ceiling is 48.10% (Codex + GPT-5.5, xhigh) at 39.74perrun,withClaudeCode+Opus4.7(max)closingto46.609.58. Cost-efficient points are Pi + MiniMax M3 (43.23% / $3.39) and Pi + Kimi K2.5 (37.80% / $2.67). Even at the top, the answerer still gets more than half the questions wrong.
Oracle ceiling on ATM-Bench-Hard.
| Model | QS (gold context) |
|---|---|
| GPT-5.5 | 71.49% |
| GPT-5 | 66.05% |
| GPT-5.4 | 65.19% |
| Gemini 2.5 Pro | 64.30% |
| Claude Opus 4.5 | 62.70% |
| Qwen3.6-27B | 62.30% |
| MiniMax M3 | 61.80% |
| Claude Sonnet 4.5 | 61.90% |
| Gemini 3 Flash | 60.10% |
| Gemini 3.1 Pro | 55.40% |
| MiMo V2.5 | 52.10% |
| Gemini 3.1 Flash Lite | 45.70% |
Even with the exact correct evidence pre-injected, the best model (GPT-5.5) hits 71.49% on Hard. The remaining ~28% is questions where evidence is genuinely ambiguous, where multiple correct answers exist, and where the model and human annotator disagree on what counts as the answer. Oracle is a noisy ceiling.
The NIAH-raw result (multimodal haystack, gold evidence among distractors). Schema-Guided Memory scaffold, Qwen3-VL-8B-Instruct answerer, real photos/videos/emails as distractors:
| Setting | QS | Context size |
|---|---|---|
| Oracle (no distractors) | 40.14% | ~6.5K tokens |
| + 25 distractors | 25.43% | ~18K tokens |
| + 50 distractors | 24.87% | ~31K tokens |
| + 100 distractors | 10.90% | ~60K tokens |
Accuracy drops from 40% to 11% as the context grows from 6.5K to 60K tokens. 60K is not long by modern standards — many models claim million-token windows — but the long-context machinery still fails on messy, multimodal, personal data. The bottleneck is comprehension, not capacity. Larger multimodal answerers handle the same sweep much better (Qwen3.6-27B: 62.30% Oracle / 50.50% @ NIAH-25; MiniMax M3: 61.80% / 41.80% @ NIAH-25) — but most still fail at NIAH-50/100 due to API image-count or payload caps, which is itself a signal about how far today’s serving stacks are from “million-token multimodal memory.”
What SGM buys you. Across Pi, Codex, Claude Code and OpenCode the leaderboard tracks SGM-on vs SGM-off variants. The deltas are large and consistent:
| Harness | Model | QS (with SGM) | QS (without SGM) |
|---|---|---|---|
| Claude Code | Claude Opus 4.7 | 46.60% | 23.10% |
| Codex | GPT-5.2 | 39.70% | 16.30% |
| Pi | MiMo V2.5 | 36.10% | 18.60% |
| Pi | Qwen3.6-27B | 38.53% | 16.59% |
| Pi | MiMo V2.5 Pro | 31.95% | 14.63% |
| OpenCode | Kimi K2.5 | 30.30% | 6.50% |
SGM more than doubles the QS on every harness/model pair — typically a +15 to +24 point lift with no change to the underlying answerer. This is the central architectural takeaway: structure beats description, even before you improve the model.
Conclusion
ATM-Bench reframes long-term personalised memory QA as three concrete sub-problems (personalised reference resolution, conflict resolution, cross-modal association) and gives the field a way to measure progress on each. The benchmark is fully open — paper, code, dataset, leaderboard — and runs end-to-end in a few GPU-hours.
The current state of the field, on this benchmark, is striking: specialised memory systems sit in a 3–14% band, agents brute-force their way to ~48% (Codex + GPT-5.5) at ~$40/run, and even the Oracle tops out at ~71% (GPT-5.5). The gap between Oracle and perfection says current models cannot reliably reason over personal memory even with perfect retrieval. The gap between Oracle and every system says no current architecture knows how to organise a person’s life.
SGM is one architectural bet that helps — and the leaderboard’s SGM-on / SGM-off comparisons suggest the bet is large: switching on a structured-memory scaffold more than doubles QS across every harness/model pair tested. The leaderboard at atmbench.github.io/leaderboard.html is the place to publish the next one.
If you build memory systems, RAG pipelines, or autonomous agents that touch personal data, please run ATM-Bench and submit. Even a low score is useful — it tells us where the field actually stands, not where the press releases say it stands.
Citation
1
2
3
4
5
6
@article{mei2026atm,
title={According to Me: Long-Term Personalized Referential Memory QA},
author={Mei, Jingbiao and Chen, Jinghong and Yang, Guangyu and Hou, Xinyu and Li, Margaret and Byrne, Bill},
journal={arXiv preprint arXiv:2603.01990},
year={2026}
}
Jingbiao Mei is a final-year PhD student at the University of Cambridge’s Machine Intelligence Lab, working on multimodal retrieval, agent systems, and the memory problems that don’t fit in a chat window. He is the creator of ATM-Bench, FLMR, PreFLMR, ExPO-HM, RA-HMD, RGCL, and Tokdash.
Comments