- Paper: arxiv.org/abs/2603.01990
- Code: github.com/JingbiaoMei/ATM-Bench
- Dataset: huggingface.co/datasets/Jingbiao/ATM-Bench
- Project Page: atmbench.github.io
Ask your AI assistant or OpenClaw this: “What was the gift I bought for my mom during our Japan trip last year — is it still under warranty?”
Simple, right? Your brain instantly cross-references: Japan trip → mom → gift → purchase date → warranty period. Five memory fragments, stitched together in milliseconds.
Now try asking ChatGPT. Or Claude. Or Gemini. Or any “AI assistant with memory.”
They can’t do it. Not even close.
I know this because I spent four years building a benchmark to test exactly this — and the results are devastating.
The Setup: 4 Years of Real Life as a Test Suite
During my PhD at Cambridge, I built ATM-Bench (According To Me), the first benchmark for long-term personalized memory QA. Not from synthetic conversations or curated datasets — from my actual life:
- ~4 years of personal data
- Photos from my phone (travel, food, friends, daily life)
- Videos of important moments
- Emails (booking confirmations, university correspondence, receipts)
- 1,069 human-annotated question-answer pairs, each with ground-truth evidence
The questions aren’t trivia. They’re the kind of thing you’d actually ask a personal assistant:
“Show me the moments where Grace was trying to be sneaky…”
“Which restaurant in Sligo did we go to on January 30th around 8pm?”
“What was the flight confirmation number for my Lyon trip?”
Each question requires resolving personalized references — names, places, events that only make sense in the context of my life. Some require piecing together evidence from multiple sources (a photo’s GPS + an email’s timestamp). Some involve conflicting evidence (two different dates for the same event).
This is what real memory looks like. And current AI systems are terrible at it.
Three Core Challenges
ATM-Bench is designed to expose three fundamental challenges that make long-term personalized memory QA uniquely difficult:
Challenge 1: Personalized Reference Resolution
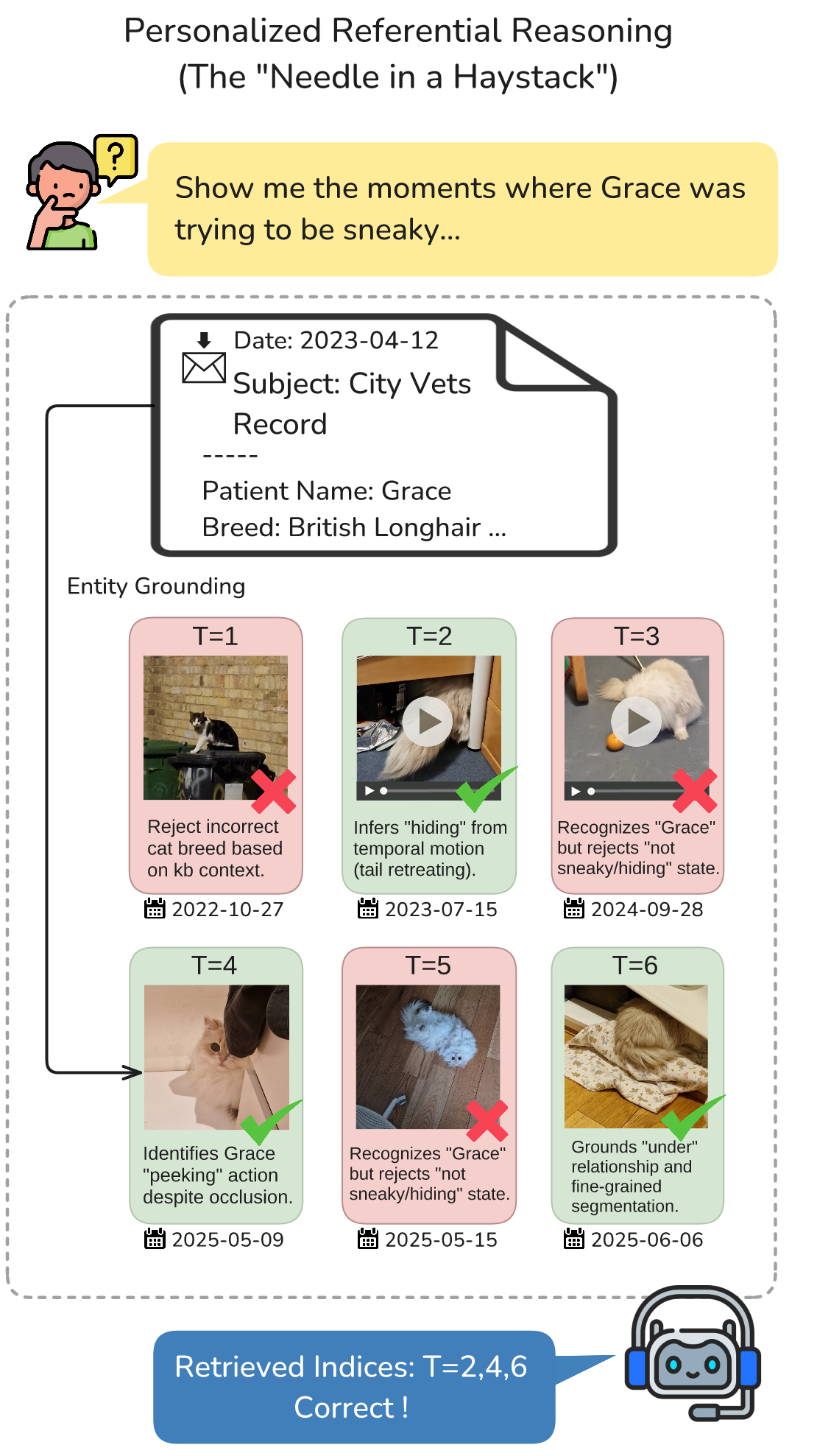
Example: “I want to edit a video for Xiaohongshu — help me find the moments where Grace was being sneaky.”
This requires the AI to:
- Determine who “Grace” is (friend, family, or pet?)
- Identify this entity across photos and videos
- Understand subjective descriptions like “sneaky”
The AI must do more than “see” — it must understand your personal context.
Challenge 2: Conflict Resolution

Example: “How much did I spend on my recent hotel stay in Portugal?”
This seemingly simple question often has multiple conflicting answers:
- A booking confirmation email
- A final invoice
- A credit card receipt
The challenge isn’t finding these documents — it’s determining which one represents the final answer. Even GPT-5 often grabs the outdated booking email instead of the actual invoice.
Challenge 3: Cross-Modal Association

Example: “What did I order at the Fancett restaurant?”
The trap: “Fancett” only appears in the email confirmation — the photos themselves have no GPS tags!
To answer this, the AI must:
- Find the Fancett reservation in emails
- Extract the timestamp and establish a time window
- Cross-reference to photos from that time period
- Visually identify what food was ordered
This is multi-hop reasoning across modalities — something current AI struggles with profoundly.
The Results: A Triple Ceiling
Here’s what we found, testing 5 state-of-the-art memory systems, standard RAG baselines, and general-purpose coding agents:
Ceiling 1: Specialized Memory Systems (< 20%)
We tested A-Mem, HippoRAG2, mem0, MemoryOS, and our own MMRAG baseline. On ATM-Bench-Hard:
Best accuracy: under 20%.
These systems were designed for memory. They have sophisticated retrieval, knowledge graphs, structured storage. And they still fail catastrophically on real personalized queries.
The core problem? They were built for dialogue history, not lived experience. When your “memory” is photos, videos, and emails spanning years, the retrieval problem changes fundamentally.
Ceiling 2: General-Purpose Agents (~34-40%)
We recently benchmarked coding agents — Claude Code, Codex, and OpenCode — giving them direct file access to all memory data:
| Agent | Model | Accuracy (QS) | Tokens Used |
|---|---|---|---|
| Codex | GPT-5.2 | 39.7% | 15.46M |
| Claude Code | Claude Opus 4.6 | 33.8% | 4.93M |
| OpenCode | Kimi K2.5 | 30.3% | 8.46M |
| OpenCode | GLM-5 | 27.0% | 16.89M |
| OpenClaw | Kimi K2.5 | 25.4% | 9.63M |
| OpenCode | MiniMax M2.5 | 22.9% | 14.5M |
Better than specialized systems — they can at least explore the data — but still far from reliable. Codex burned through 15.46 million tokens per run to achieve 40%. That’s roughly $30-50 in API costs to answer a set of personal questions, and it still gets 6 out of 10 wrong.
Ceiling 3: Oracle (72%)
Even when we hand the model the exact correct evidence (no retrieval needed), GPT-5 with reasoning only reaches 72%. The remaining 28% failures come from:
- Inability to resolve personalized references
- Failure to reason across multiple evidence pieces
- Confusion when evidence conflicts
This is the bitter lesson: the problem isn’t just retrieval. Even with perfect retrieval, current models can’t reliably reason over personal memory.
The Needle in a Haystack Problem
We also ran Needle In A Haystack (NIAH) experiments, giving models the correct evidence buried among distractors:
| Setting | Accuracy | Context Size |
|---|---|---|
| Oracle (just the evidence) | 40.14% | 5.7k tokens |
| 25 distractors | 25.43% | 15.9k tokens |
| 50 distractors | 24.87% | 29k tokens |
| 100 distractors | 10.90% | 56k tokens |
Performance drops from 40% to 11% as context grows. And 56k tokens isn’t even long by modern standards — many models claim million-token context windows. The issue isn’t context length; it’s context comprehension with personalized, multimodal data.
Key insight: Long-term memory QA isn’t just a retrieval problem — it’s also an anti-interference filtering, cross-evidence integration, and multi-step reasoning problem.
Why This Matters
Every major AI company is betting on personal AI assistants. Apple Intelligence, Google Gemini, ChatGPT with memory, Microsoft Copilot — all promise to “know you” and help you with your life.
But here’s what ATM-Bench reveals:
1. Long context ≠ long-term memory. You can have a million-token context window and still fail at remembering what happened last Tuesday. Real memory requires organization, not just capacity.
2. Text-only memory is a dead end. Human life is multimodal. The photo of a restaurant, the booking email, the video of a birthday party — these are the raw materials of personal memory. Systems that only remember text conversations are missing most of the picture.
3. Personalized references are the core unsolved problem. When I say “Grace” or “that trip” or “the usual place,” I’m invoking a personal knowledge graph that no current system can build or query reliably. This is fundamentally harder than general knowledge QA.
4. General-purpose agents aren’t the answer (yet). Throwing a coding agent at the problem improves over specialized systems, but at enormous cost and still poor accuracy. We need architecturally different approaches.
A Potential Direction: Schema-Guided Memory
One finding from ATM-Bench gives me hope. We proposed Schema-Guided Memory (SGM) — representing each memory item with structured fields (time, location, entities, tags) instead of free-form descriptions.
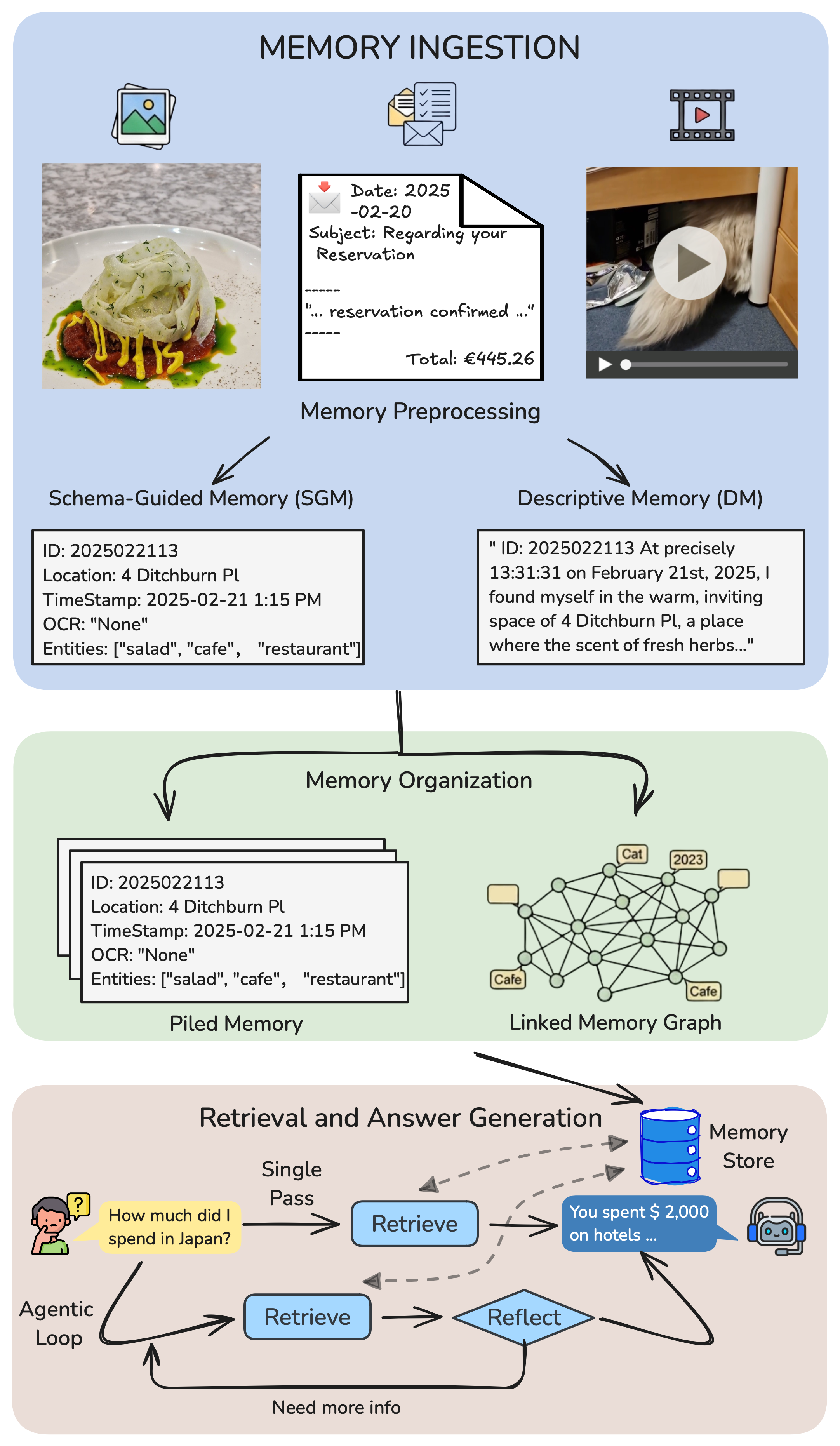
SGM consistently outperforms the commonly used “Descriptive Memory” approach. Why? Because structure makes retrieval tractable. When you search for “dinner in Sligo on January 30th,” structured fields let you filter by location and time before matching content. Free-form descriptions force the model to parse everything.
This isn’t a solution — SGM still tops out well under 30% on the hard set. But it suggests the right direction: explicit structure over implicit understanding.
The Bitter Lesson, Reframed
Rich Sutton’s famous “Bitter Lesson” argues that general methods leveraging computation beat human-engineered approaches. For personal memory, I’d frame the bitter lesson differently:
Neither scaling nor engineering has cracked personal memory.
- Scaling context windows doesn’t help (NIAH shows performance degrades with more context)
- Scaling compute doesn’t help efficiently (15M tokens for 40% accuracy)
- Engineered memory systems don’t help (< 20% with sophisticated architectures)
What might help? I genuinely don’t know yet. But ATM-Bench gives us, for the first time, a way to measure progress honestly. No more claiming your memory system works because it can recall what was said three turns ago in a scripted conversation.
Real memory is messy, multimodal, and deeply personal. Until AI systems can handle that, the promise of “personal AI” remains exactly that — a promise.
Dataset and Code
ATM-Bench is fully open-source:
- 📄 Paper: arxiv.org/abs/2603.01990
- 💻 Code: github.com/JingbiaoMei/ATM-Bench
- 🤗 Dataset: huggingface.co/datasets/Jingbiao/ATM-Bench
- 🌐 Project Page: atmbench.github.io
The dataset includes:
- 1,069 QA pairs with ground-truth evidence annotations
- ~4 years of multimodal personal data (photos, videos, emails)
- Hard subset with complex reasoning requirements
- NIAH evaluation support for context scaling studies
If you’re building a personal AI assistant, a memory system, or just curious how well your favorite model handles real-world memory — benchmark it. The results will probably surprise you.
And not in a good way.
Citation
If you found this work interesting, please consider citing:
1
2
3
4
5
6
@article{mei2026atm,
title={According to Me: Long-Term Personalized Referential Memory QA},
author={Mei, Jingbiao and Chen, Jinghong and Yang, Guangyu and Hou, Xinyu and Li, Margaret and Byrne, Bill},
journal={arXiv preprint arXiv:2603.01990},
year={2026}
}
Jingbiao Mei is a final-year PhD student at the University of Cambridge, working on multimodal content moderation, retrieval-augmented systems and AI Agents.